The Xamarin platform allows developing iOS and Android applications entirely in C#. Sometimes, however, some legacy code may be too large or complex to make porting it to C# for your mobile app worthwhile. Most examples found online show you how to use existing Objective-C libraries in Xamarin.iOS and existing Java libraries in Xamarin.Android. However, it is entirely possible to call C code from a Xamarin app. Microsoft’s recent support for C/C++ on iOS and Android in Visual Studio can make this a simple task.
You will need the sources for the code you want to call to compile it for iOS and Android. The code cannot access any libraries which you only have binaries for that have been compiled for other platforms.
To get started, create a new C++ cross-platform project using Visual Studio 2015.
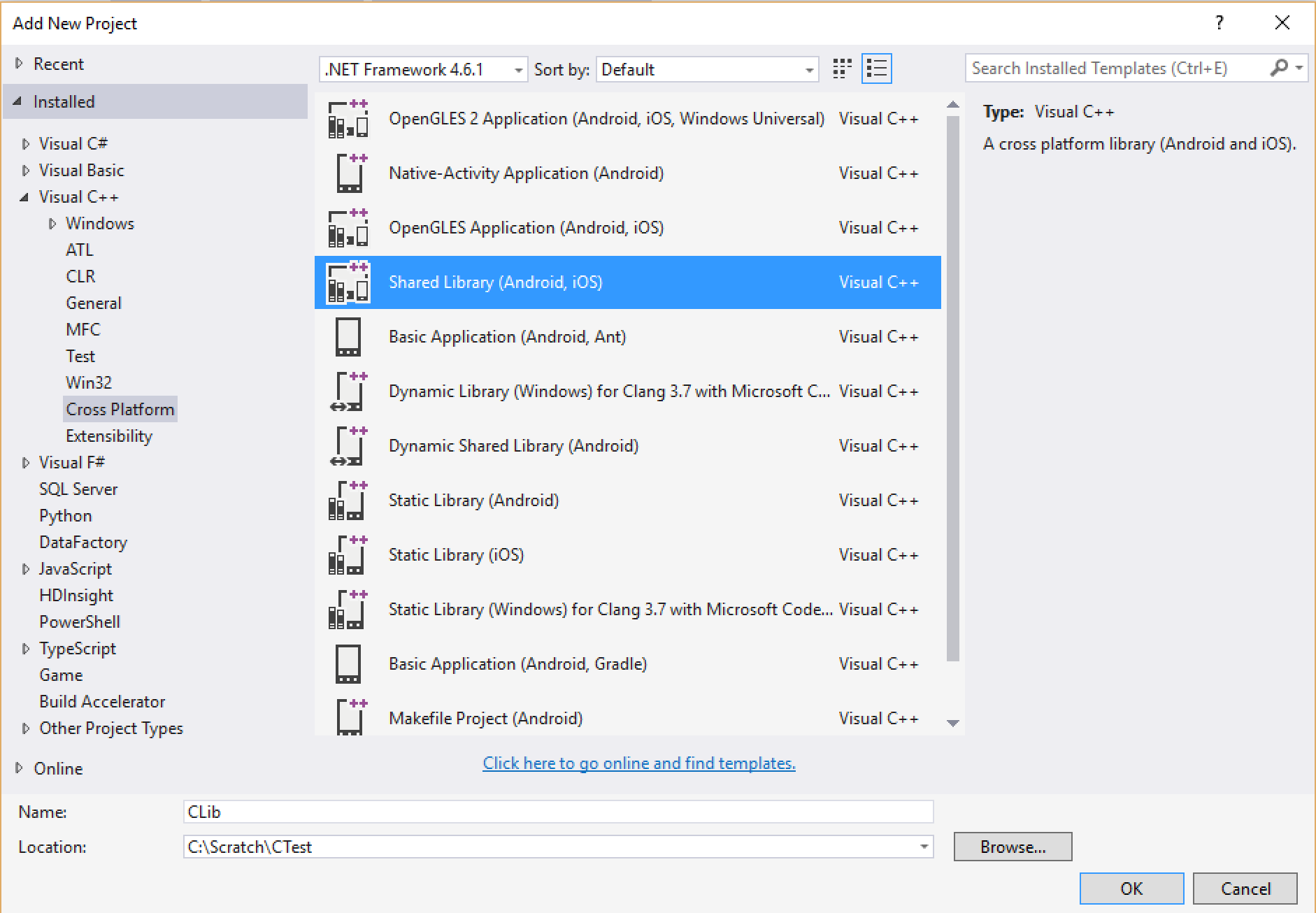
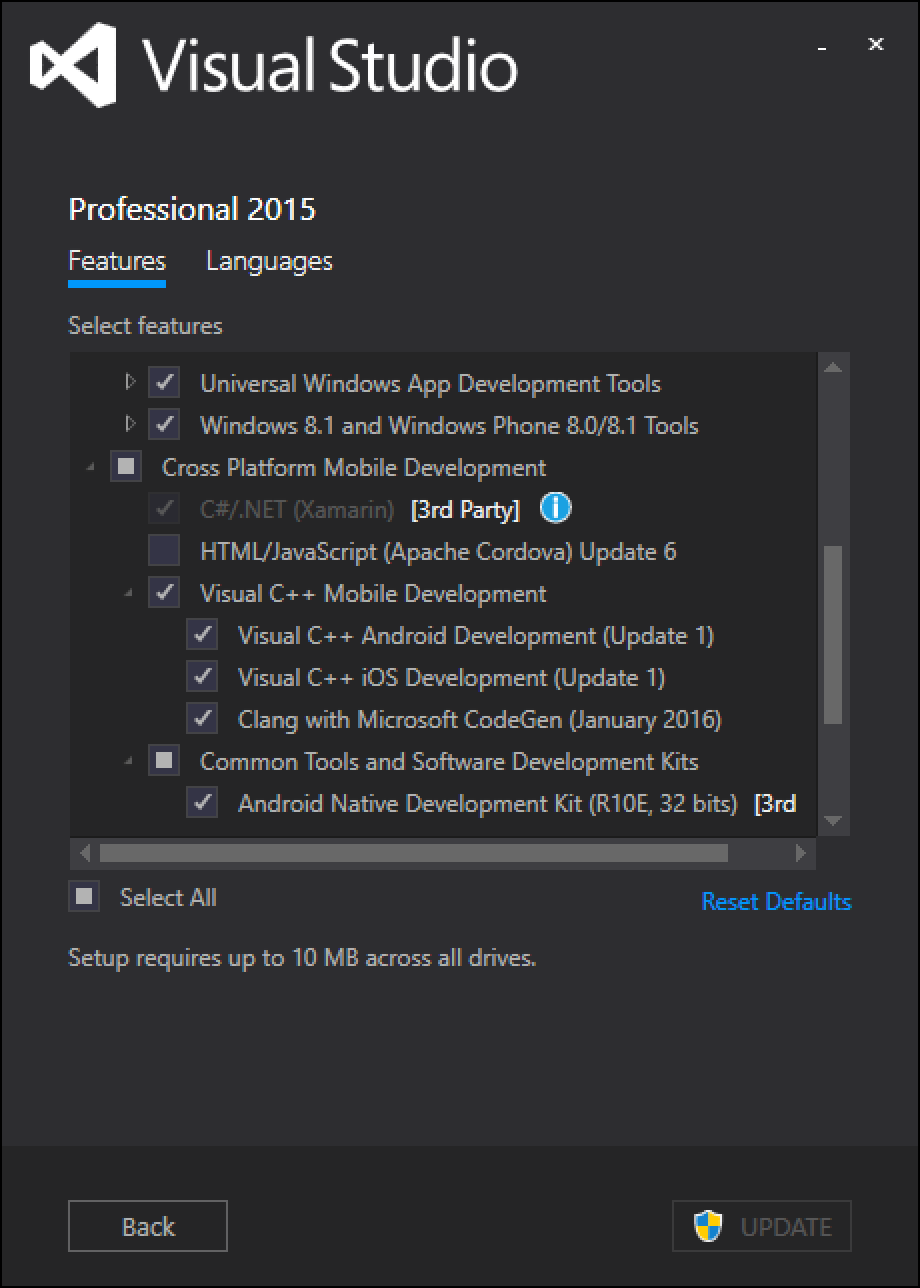
You will need to have the corresponding Visual Studio package installed to have this option available.
This will create three projects: one for Android, one for iOS, and a shared project.
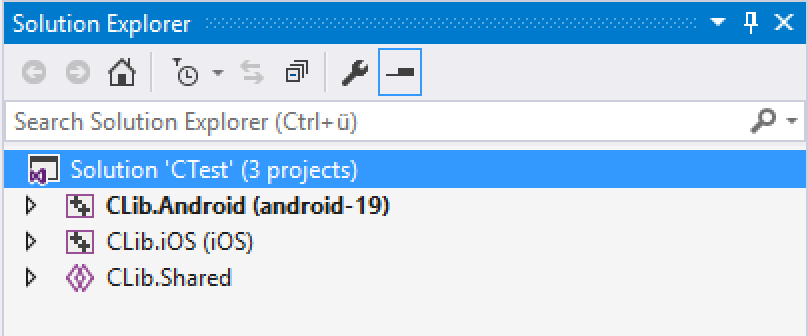
It is important to understand the shared project concept for this. The code in the shared project does not result in a DLL or library being generated. A shared project can hold any type of file. Projects referencing the shared project can access code from any file in the shared project. The code will then be compiled in the context of the referencing project. If code is not referenced, it is not compiled. For this reason, it is necessary to have calls into all code needed contained in the platform-specific projects. This means that the platform-specific C/C++ projects need to contain code, too. This code can be identical in the Android and iOS projects and reside in the same files. Unlike in .NET projects, file linking is not needed for C++ projects; source code files do not have to reside inside a project’s folder or subfolder.
In the example, I’ve created a simple function clib_add_internal() that add two integers and resides in the shared project.
This code is called from a function in the platform-specific projects.
For the example code, this doesn’t make any sense. For a real project, you will put any call that needs to be directly invoked from the .NET code (your interface) into the platform-specific projects while underlying code can reside in the shared project.
The calls from .NET will be using P/Invoke since C++/CLI is not available on iOS or Android. So the basic P/Invoke rules apply for your interface’s code: Either the code is plain C or, if you are using C++, the calls are either plain functions or static methods and contain only POC parameters and return values.
For the iOS project, the output format needs to be changed to a static library (.a file) since iOS does not allow dynamically loading code. For Android, a dynamic library (.so) should be built.
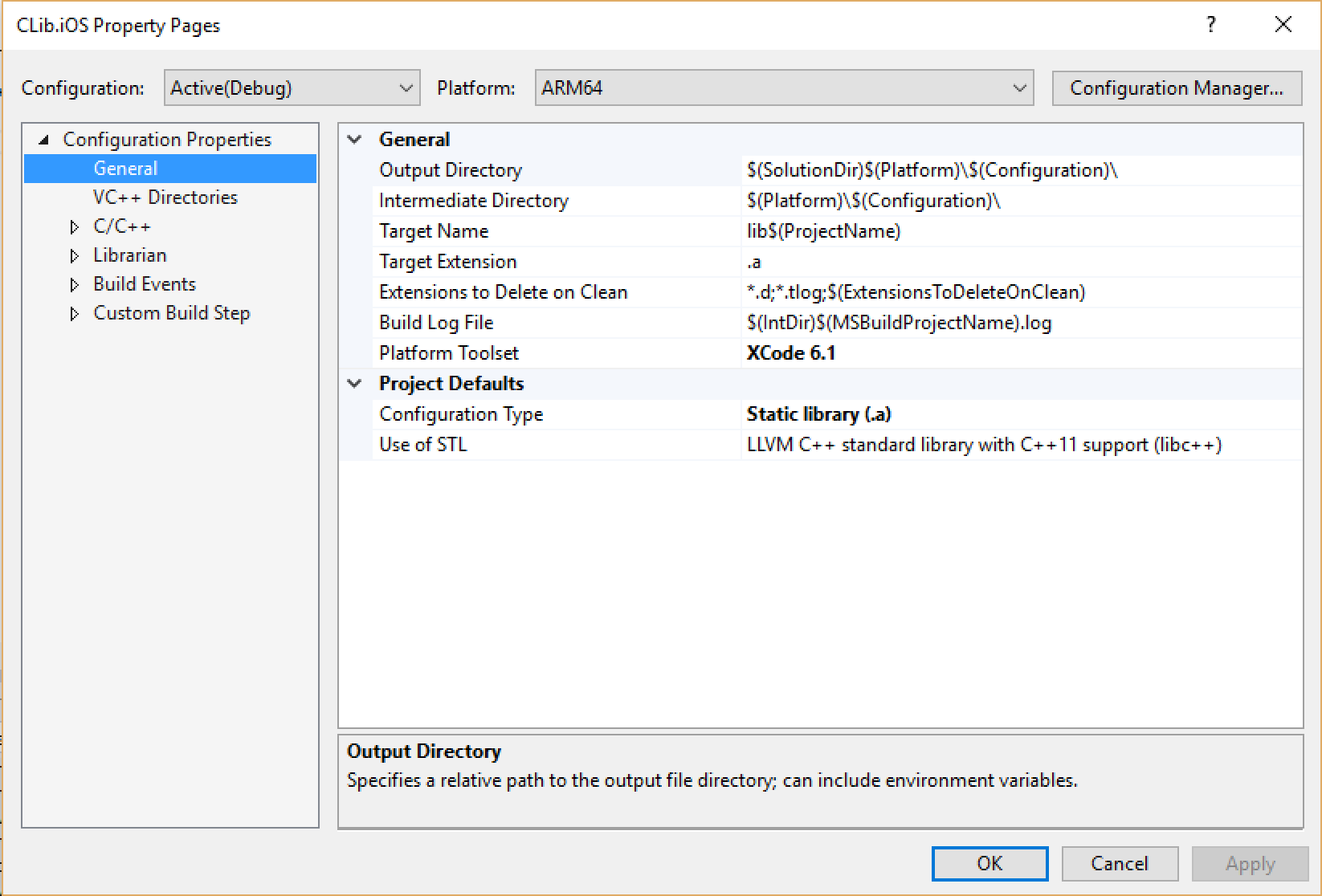
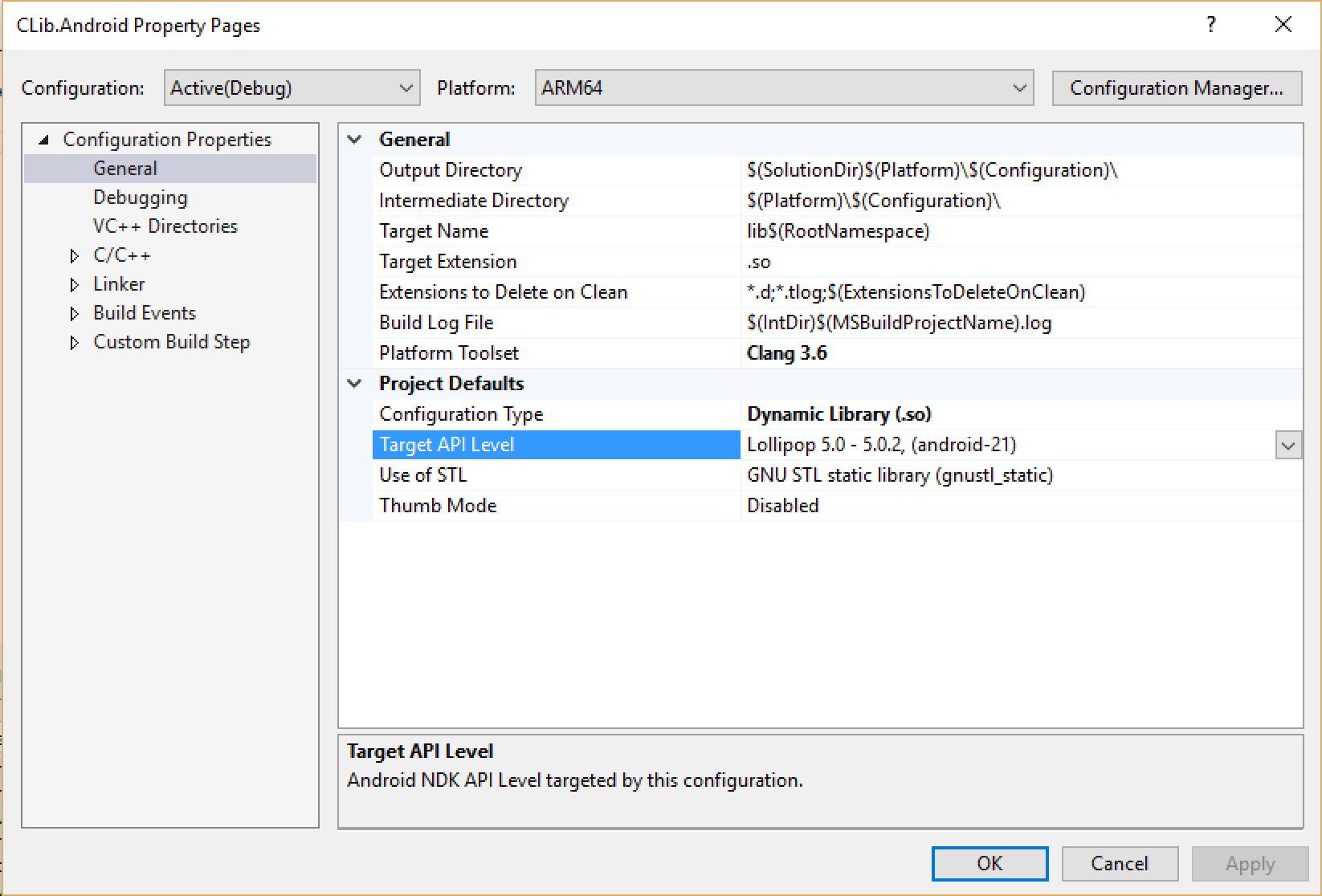
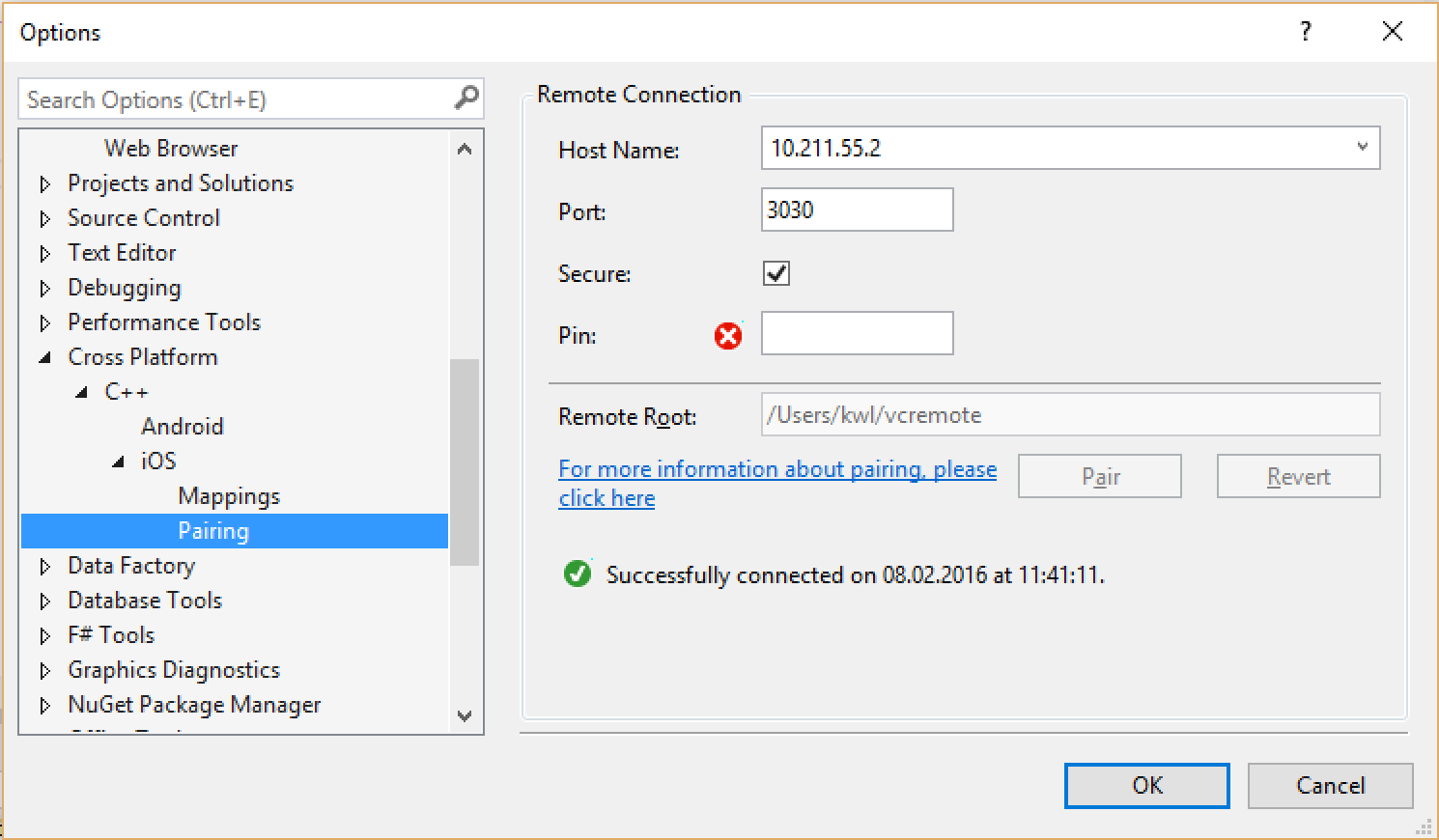
While the Android library can be compiled within Visual Studio, compiling the iOS library needs a connection to a build agent on the Mac. This is not the regular Xamarin.iOS installation on a Mac but a Microsoft tool that is installed on OS X using npm. Visual Studio will communicate with this tool through TCP/IP.
To call the native code, create a Xamarin project for iOS and Android each. Include the native libraries in the respective Xamarin projects.
On iOS, if you’re targeting multiple processor architectures (either supporting pre-iPhone 5s or supporting the simulator), you can build the iOS project for multiple platforms using the dropdown in the toolbar. Then, combine the libraries into one using lipo according the Xamarin docs. On Android, you’ll need to modify the .csproj according to the Xamarin documentation to specify the .so files for each platform.
The calls into the native code are regular P/Invoke calls (although DLLs don’t play a role here). On Android, you specify the name of the shared library.
On iOS, use the special Mono name __Internal to call into the static library.
And that’s it! You can find the example code at https://github.com/lothrop/XamarinNative. In the example, I put the C# marshaling code into another shared project that is referenced by the Xamarin.iOS and Xamarin.Android projects.
